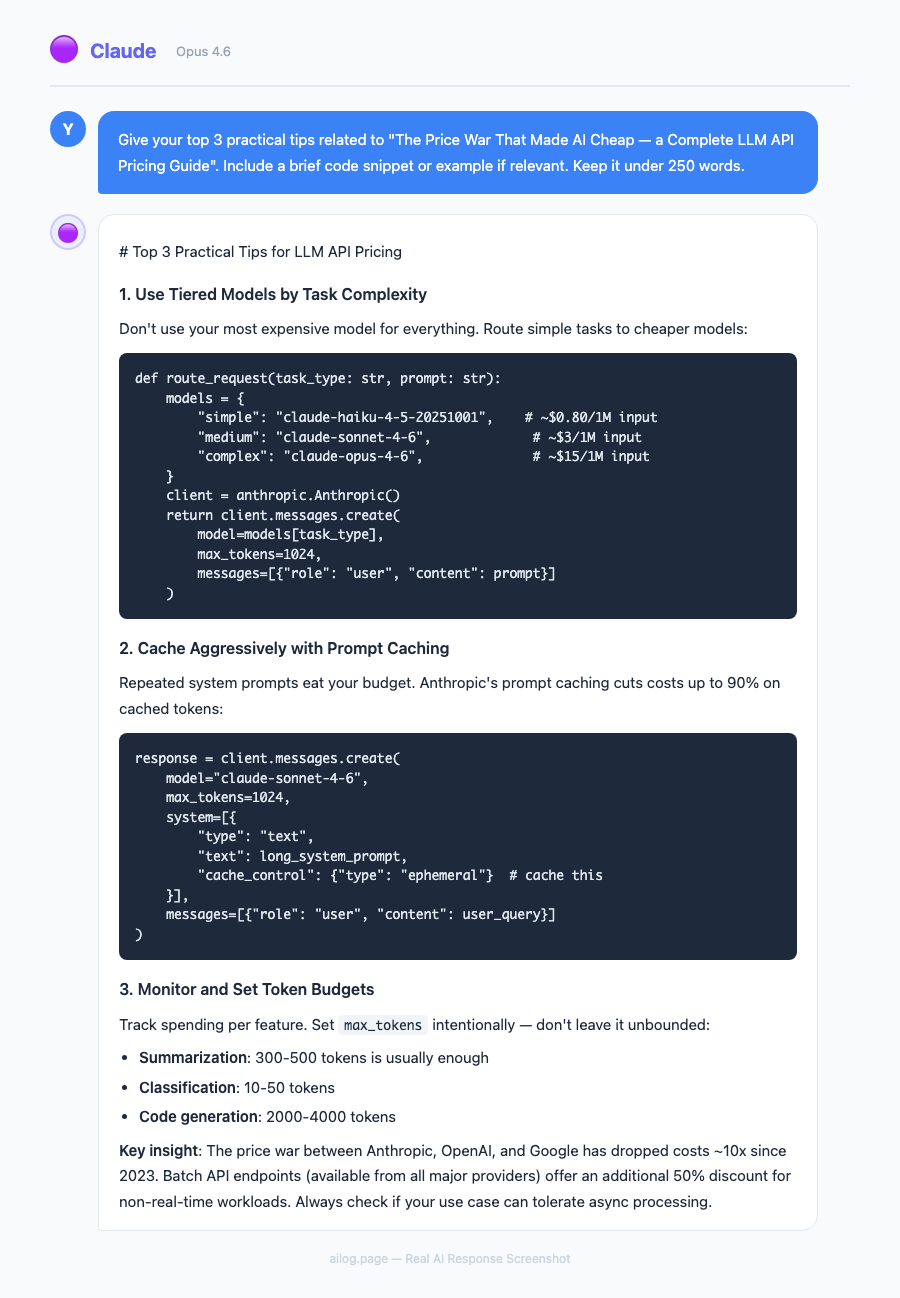
The Price War That Made AI Cheap — a Complete LLM API Pricing Guide
LLM API prices dropped 80% in a year. Here's every major model's pricing, the hidden costs developers miss, and 6 optimization strategies that save 70-90%.
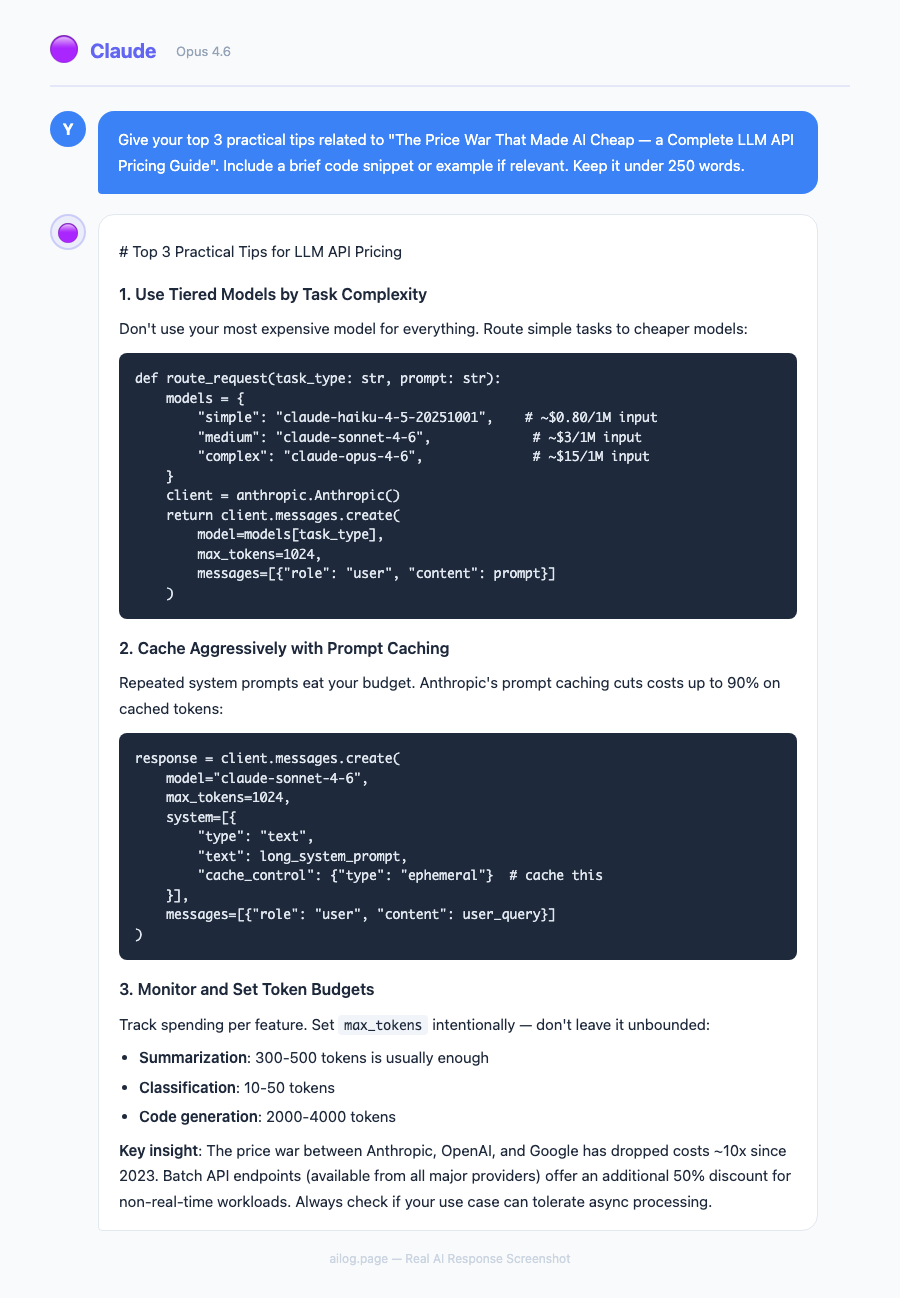
• LLM API prices dropped over 80% in the past year, with DeepSeek offering rates 90%+ cheaper than GPT-5
• The gap between cheapest and most expensive models is over 1,000x — model selection matters enormously
• Prompt caching, batch APIs, and model tiering can cut your AI bill by 70-90% without sacrificing quality
• For most production workloads, mid-tier models ($1-3/M input) deliver 95% of frontier model performance
• The real cost isn't per-token pricing — it's output tokens, which cost 3-8x more than input tokens
What's Inside
- The Current Pricing Landscape
- Every Major Model, One Table
- The Hidden Costs Most Developers Miss
- 6 Ways to Cut Your LLM API Bill
- Picking the Right Model for Your Use Case
- The Open-Source Alternative
- Cost Calculator: Real-World Scenarios
- FAQ
The Current Pricing Landscape
A year ago, using frontier AI models at scale was expensive enough to make most startups flinch. GPT-4's initial pricing set the standard at $30/$60 per million input/output tokens. Today, GPT-5 delivers better performance at $1.25/$10 — a 95% price reduction for superior capability.
This price collapse happened for three reasons: competition from Google, Anthropic, and open-source models forced aggressive pricing; infrastructure improvements reduced the cost of running inference; and new architectures (mixture-of-experts, speculative decoding) made smaller models punch above their weight.
The result is a market where the difference between the cheapest usable model and the most expensive frontier model spans over 1,000x. Choosing the right model for each task isn't just optimization — it's the difference between a viable product and a money pit.
Every Major Model, One Table
All prices are per million tokens. Input is what you send to the model. Output is what the model generates. Output tokens always cost more because they require more compute.
| Provider | Model | Input ($/M) | Output ($/M) | Context |
|---|---|---|---|---|
| OpenAI | ||||
| GPT-5 | $1.25 | $10.00 | 400K | |
| GPT-5 mini | $0.30 | $1.25 | 128K | |
| GPT-5 Pro | $2.50 | $15.00 | 400K | |
| GPT-4o | $2.50 | $10.00 | 128K | |
| GPT-4o mini | $0.15 | $0.60 | 128K | |
| Anthropic | ||||
| Claude Sonnet | $3.00 | $15.00 | 200K | |
| Claude Haiku | $0.25 | $1.25 | 200K | |
| Claude Opus | $15.00 | $75.00 | 200K | |
| Gemini 1.5 Pro | $1.25 | $5.00 | 2M | |
| Gemini 1.5 Flash | $0.075 | $0.30 | 1M | |
| DeepSeek | ||||
| DeepSeek V3 | $0.27 | $1.10 | 128K | |
| DeepSeek V3 (cached) | $0.027 | $1.10 | 128K | |
| xAI | ||||
| Grok-2 | $2.00 | $10.00 | 131K | |
| Meta (via API providers) | ||||
| Llama 3.1 405B | $0.80 | $0.80 | 128K | |
| Llama 3.1 70B | $0.20 | $0.20 | 128K | |
Prices as of November 2025. Pricing changes frequently — verify at OpenAI, Anthropic, and Google before committing.
The Headline Numbers
The cheapest option for basic tasks: Gemini 1.5 Flash at $0.075/$0.30. For a million input tokens (roughly 750,000 words), you pay less than a cup of coffee. This model handles summarization, classification, and simple generation well enough for most non-critical applications.
The best value for complex tasks: GPT-5 at $1.25/$10. It outperforms GPT-4o while costing less for input tokens. The reasoning capabilities justify the output token premium for tasks that require multi-step analysis.
The quality-per-dollar sweet spot: Claude Haiku at $0.25/$1.25. It delivers surprisingly strong performance for its price point, especially on coding and instruction-following tasks. Many production systems route 70%+ of requests through Haiku and only escalate to Sonnet for complex queries.
The Hidden Costs Most Developers Miss
Output Tokens Are the Real Expense
Most developers focus on input pricing, but output tokens cost 3-8x more than input tokens across every provider. A chatbot that generates verbose responses can cost 5-10x more than one tuned for concise answers. Telling the model to "be concise" or "respond in under 200 words" can cut your bill in half without reducing usefulness.
Reasoning Tokens Count (and They're Expensive)
Models with reasoning capabilities (GPT-5, Claude with extended thinking) generate "thinking tokens" that count toward your output token usage. A single complex reasoning query can generate 2,000-5,000 thinking tokens before producing a 200-token answer. For batch processing, this adds up fast.
Context Window Waste
Sending your entire system prompt (often 2,000-5,000 tokens) with every API call adds up. If you make 100,000 API calls per month with a 3,000-token system prompt, that's 300 million input tokens just on system prompts — about $375/month at GPT-5 rates, or $22.50 at Gemini Flash rates.
Retry Costs
Failed requests that need retrying, responses that need regeneration, and validation loops all multiply your effective cost. Budget 15-25% above your calculated token usage for production applications.
6 Ways to Cut Your LLM API Bill
1. Model Tiering (Save 60-80%)
Route simple tasks to cheap models and complex tasks to expensive ones. In practice, this means:
- Tier 1 (Gemini Flash, GPT-4o mini): Classification, simple extraction, formatting — 60-70% of requests
- Tier 2 (Claude Haiku, GPT-5 mini): Moderate generation, summarization — 20-25% of requests
- Tier 3 (GPT-5, Claude Sonnet): Complex reasoning, coding, analysis — 5-15% of requests
A routing classifier (which itself costs almost nothing to run) determines the tier for each request. You can use a simple keyword-based router or a small language model (Haiku-class) to classify incoming requests by complexity. The classifier itself costs $5-15/month for most workloads. This single optimization typically reduces costs by 60-80% compared to sending everything to a frontier model.
In my own production systems, I route about 65% of traffic to Gemini Flash, 25% to Claude Haiku, and 10% to Claude Sonnet. The blended cost per request is roughly $0.002 — compared to $0.018 if everything went through Sonnet. That's a 9x cost reduction with no measurable quality degradation for end users.
2. Prompt Caching (Save 75-90%)
Anthropic and OpenAI both offer prompt caching that dramatically reduces costs for repeated context. If your system prompt stays the same across requests, cached input tokens cost just 10% of the standard rate. For applications with large, stable context (RAG systems, document analysis), caching is the single highest-impact optimization.
3. Batch APIs (Save 50%)
If your workload isn't real-time, batch APIs offer 50% discounts. OpenAI's Batch API, Anthropic's Message Batches, and Google's batch endpoints all return results within 24 hours at half price. Content generation, data processing, and overnight analysis jobs are ideal candidates.
4. Output Length Control (Save 30-50%)
Explicit instructions to limit response length directly reduce output token costs. Compare the cost difference:
Without length controlAverage response: 800 tokens
1M requests/month: $8,000 (GPT-5)With length controlAverage response: 300 tokens
1M requests/month: $3,000 (GPT-5)
5. Switch Providers for Specific Tasks
No single provider is cheapest for everything. DeepSeek V3 with caching is 45x cheaper than GPT-5 for input tokens. For workloads where quality differences are minimal (data extraction, reformatting, classification), routing to the cheapest adequate provider saves significantly.
6. Fine-Tune Smaller Models
A fine-tuned GPT-4o mini or Llama 70B often matches a frontier model on specific tasks at a fraction of the cost. The upfront investment in fine-tuning ($50-500 depending on dataset size) pays back quickly at scale. For any task you perform more than 100,000 times per month, investigate fine-tuning.
Picking the Right Model for Your Use Case
| Use Case | Recommended Model | Monthly Cost (100K requests) |
|---|---|---|
| Customer support chatbot | Claude Haiku / GPT-5 mini | $150-300 |
| Code generation (IDE) | Claude Sonnet / GPT-5 | $500-1,200 |
| Document summarization | Gemini 1.5 Flash | $30-80 |
| Content generation | Claude Sonnet / GPT-5 | $800-2,000 |
| Data extraction/parsing | GPT-4o mini / Gemini Flash | $15-60 |
| Complex reasoning/analysis | GPT-5 Pro / Claude Opus | $2,000-8,000 |
The cost differences are staggering. A document summarization pipeline on Gemini Flash costs $30-80/month for 100K requests. The same pipeline on Claude Opus would cost $8,000+. For summarization, the quality difference doesn't justify a 100x cost increase.
The Open-Source Alternative
The pricing table above only covers commercial APIs. But the fastest-growing segment of the LLM market is open-source models that you can self-host or access through third-party API providers at dramatically lower prices. This option deserves serious consideration for any production workload.
Self-hosting open-source models eliminates per-token costs entirely, replacing them with fixed infrastructure costs. The trade-off equation:
- Llama 3.1 70B on a single A100 GPU: ~$1.50/hour cloud cost, handles ~50 requests/minute. If you process 2M+ requests/month, self-hosting is cheaper than API pricing.
- Llama 3.1 405B: Requires 4-8 A100 GPUs (~$6-12/hour). Cost-effective only at very high volumes (5M+ requests/month).
- Smaller models (7B-13B): Can run on consumer GPUs or cheaper cloud instances. Excellent for narrow, specific tasks where a fine-tuned small model matches frontier performance.
The breakeven point varies by workload, but as a rule of thumb: if you spend over $5,000/month on LLM APIs for a single use case, investigate self-hosting. Below that threshold, the operational overhead of managing GPU infrastructure usually isn't worth it.
API providers like DeepSeek and Together AI offer open-source models via API at prices that undercut proprietary models while avoiding the infrastructure management burden. DeepSeek V3 at $0.27/$1.10 per million tokens delivers strong performance at a fraction of frontier model costs.
Cost Calculator: Real-World Scenarios
| Scenario | Cheapest Option | Cost/Month | Premium Option | Cost/Month |
|---|---|---|---|---|
| SaaS chatbot (50K conversations) | Claude Haiku | $125 | GPT-5 | $2,500 |
| Content pipeline (1K articles) | Gemini Flash | $15 | Claude Sonnet | $900 |
| Coding assistant (dev team of 10) | GPT-5 mini | $200 | Claude Sonnet | $3,000 |
| Data extraction (1M documents) | GPT-4o mini | $90 | GPT-5 | $5,625 |
Useful Resources
Related Reading
Real AI Responses (Tested March 2026)
These numbers assume average request sizes (2K input, 500 output tokens for chatbots; 5K input, 2K output for content). Your actual costs depend on prompt length, response verbosity, and caching effectiveness.
The pattern across all scenarios is consistent: the cheapest adequate model is typically 10-60x less expensive than the premium option. The key word is "adequate" — you need to test whether the cheaper model actually handles your specific task well enough. Run a small evaluation set (100-500 representative requests) through both options and compare quality before committing to the cheaper model at scale.
For startups and small teams, the cheapest column represents viable production costs. A SaaS chatbot running on Claude Haiku for $125/month is affordable for almost any business. The premium column shows what enterprises with quality-sensitive use cases might spend — still reasonable compared to the human labor these systems replace.
The Total Cost of Ownership
Raw API pricing is only part of the picture. A complete cost analysis should include prompt engineering time (cheaper models often need better prompts), evaluation and monitoring infrastructure, fallback handling when models fail or produce poor outputs, and the engineering cost of maintaining multi-model routing systems. For a team running their first LLM-powered feature, expect to spend 2-3x the raw API cost on surrounding infrastructure and engineering time. As your systems mature and processes stabilize, this overhead shrinks to about 1.3-1.5x.
FAQ
Which LLM API is the cheapest overall?
For raw per-token cost, Gemini 1.5 Flash ($0.075/$0.30) and GPT-4o mini ($0.15/$0.60) are the cheapest options from major providers. DeepSeek V3 with prompt caching can go as low as $0.027 per million input tokens. But "cheapest" only matters if the model handles your task adequately — sending complex reasoning to a Flash model wastes money on retries and poor outputs.
How much does it cost to run a ChatGPT-like application?
A consumer chatbot handling 50,000 conversations per month costs $125-2,500/month depending on model choice. Most production chatbots use a tiered approach: cheap models for simple queries (80% of traffic), frontier models for complex ones (20%), averaging $300-500/month at that volume.
Are LLM API prices still dropping?
Yes. Prices dropped roughly 80% from 2024 to 2025, and competition from open-source models and new providers continues to push costs down. Expect another 30-50% reduction over the next year, driven by inference optimization and new model architectures.
Should I use one provider or multiple?
Multiple. Each provider has different strengths and pricing. A multi-provider setup with intelligent routing can reduce costs 40-60% compared to single-provider usage. The engineering overhead of supporting multiple APIs is modest — most LLM API formats are nearly identical.
When does self-hosting make financial sense?
When you spend $5,000+/month on a single API use case and have engineering capacity to manage GPU infrastructure. For most teams, API providers (including those offering open-source models) are more cost-effective when you factor in operational overhead, reliability, and the speed of model updates.